Big Health IT
(What we need is perspective)


{kind=link}
Let’s revisit 1970, and a topic we’ve already examined.⌘ I won’t repeat Codd’s 13 rules here, though. I want to take a step back, and look at the bigger picture. Here’s a quote from Ted Codd. Once you fully grasp it, it stops being boring …
Activities of users at terminals and most application programs should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed. Changes in data representation will often be needed as a result of changes in query, update, and report traffic and natural growth in the types of stored information.
Existing noninferential, formatted data systems provide users with tree-structured files or slightly more general network models of the data. In Section 1, inadequacies of these models are discussed.
Codd then goes on (PDF) to provide a familiar solution. A solution that almost every developer either ignores, or pays lip service to, often without understanding or honouring it. It’s not ‘SQL’; it’s an approach to joining up data properly:
In contrast, the problems treated here are those of data independence—the independence of application programs and terminal activities from growth in data types and changes in data representation—and certain kinds of data inconsistency which are expected to become troublesome even in nondeductive systems. [my emphasis]
Failure to appreciate this principle destroys entire systems slowly over time.
Point missed
Perhaps I’m wrong, but across pretty much every medical database I look at, I perceive “I know better than Ted” scrawled all over. That’s not the worst problem, either. Codd’s quotes encompass a large part of the strategic failures of giant IT projects. You see, this is not just a slightly arcane and boring caution about “how to build data tables”. Normalisation must be the lifeblood of vast IT projects, and I’m convinced that failure to understand this concept is behind many (even most) catastrophic long-term failures.
Wherever you have multiple sources of ‘truth’, they must be reconciled. It seems to me that architects of multibillion dollar health IT systems have flip-flopped between huge monolithic centralised systems and huge decentralised, modular-ish systems without once even stopping to think about how they will normalise in either circumstance! Normalise they must, to avoid insertion, update and deletion anomalies—and loss of ‘referential integrity’ in their data. This is hard. Glib solutions are wrong solutions.
In the last post,⌘ we found how a specific system reportedly joined up patient data all wrong. This doesn’t surprise me. If you muck up the fundamental design, the outcome is entirely predictable: failure. Buildings need foundations.

{kind=link}
‘But monoliths work’
Someone at this point will say something like “But Jo, some of the most successful medical record systems—certified, conformant Electronic Health Records—use hierarchical tree structures where the data are tightly coupled to the functional program components. Surely you’re being unrealistic in denying their success?”
There is some truth in this statement and question. At least three vast systems (The VA’s VistA, InterSystems and Epic) use approaches that are not just hierarchical, but are based on a programming language (M, aka ‘MUMPS’) that was invented in 1966, two years before Kubrick’s film was released, and before Codd even thought up relational systems. They have been successful. Substantially more than half of the electronic records in the US are stored in such systems.
So let’s talk about them. First, VistA is indeed a complete system of clinical, administrative and financial operations, and in 2016 was still the top-rated hospital system in a Medscape poll, despite no Electronic Health Record (EHR) in that poll scoring more than 4/5. Ever. It was however already on the chopping block, as the political winds changed after the millennium. And guess what? Oracle (who bought Cerner) are still struggling to convert the data.
Epic and InterSystems similarly seem to struggle to export comprehensive, joined-up data. And no wonder! Both have reporting systems that export their hierarchical (B-tree based) data into conventional SQL format, but this results in thousands of conspicuously denormalised⌘ tables, which are difficult to manage.1
There is also the not-small matter that implementing these systems does not save time. I know this from several sources: colleagues who have worked with these systems; me myself plodding through records from the Epic-using ‘Best Hospital in the US’ during a large multinational research study; deep exposure to InterSystems products; and published evidence, where EHR introduction resulted in increased human employment. Instead, we get burnout. Scribes had to be hired to lighten the load of clinicians.2
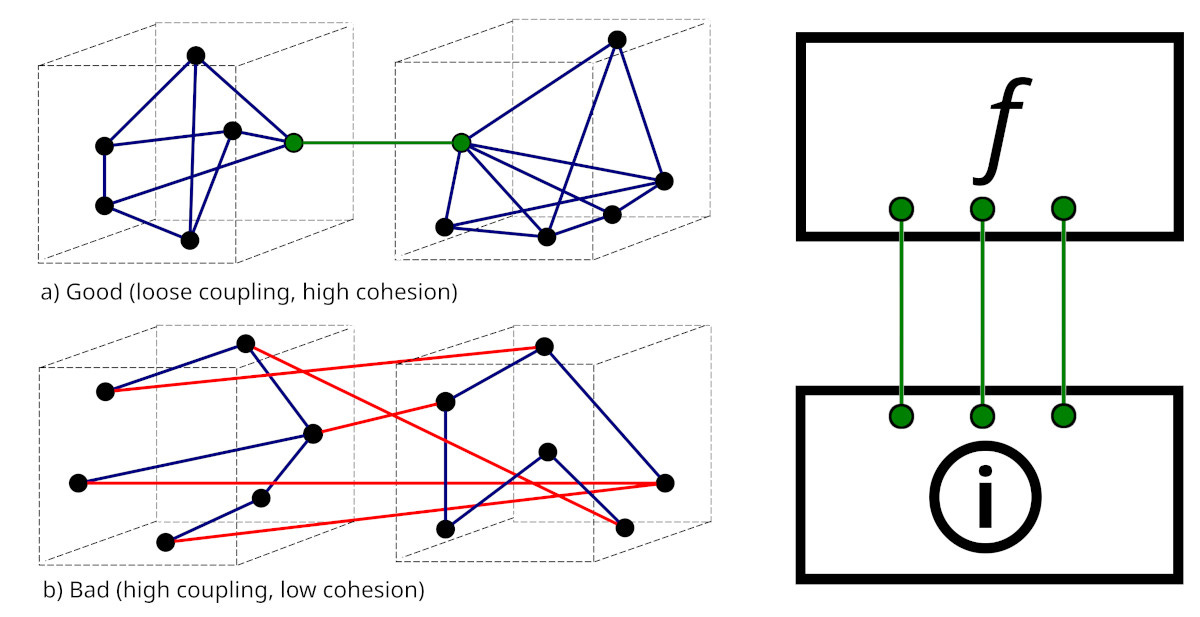
So what’s the alternative?
Anyone who has done a computer science degree will know the mantra that modules should be loosely coupled, but have high internal cohesion. This is another way to view Codd’s broader principle. Consider the above graphic. On the left, we have the standard picture (from Wikimedia). On the right, we’ve translated this into two layers, a functional layer (f) that is loosely coupled to an underlying information layer . Let’s describe the big picture more formally:
{kind=link}
There must be loose coupling between the information layer and the functional layer.
First, a bit of nit-picking. What’s the difference between data and information? I will make this very simple: information is data in context. When we join up data within a model, then we will call this ‘information’.
You can immediately see that it’s easy to muck things up: if our ‘information layer’ becomes structured around how data are used, we have a problem. To take an extreme example, if the ‘heart rate’ is stored in a different place in the information layer depending on whether it’s acquired in primary care, the cardiology cath lab, the maternity suite, a psychiatric ward or a theatre complex, well, Oops.
Once we lose the plot, tables proliferate. And this is commonly what we encounter. For example, Cerner has historically been quite proud of their 5,000–10,000 SQL tables. These seem to have arisen as Cerner acquired new extended systems, and bolted them on rather than refactoring them. As you can imagine, this sort of thing becomes very difficult to maintain.
What is our desirable model then? Loose coupling! For example, a new vendor might come along, and replace part of the functionality of an older vendor, and the coupling is so weak that the change is imperceptible. A clinician or administrator or researcher can simply acquire (from the information layer) data primarily sourced from either system, and see no issues. This sort of dreamy functionality is often talked about in the context of federation, so let’s look at this next.
Federation
Let me say this first: federation is great in principle. But the assumption of ‘federation’ carries with it certain responsibilities, and I am far from convinced that many of the most enthusiastic advocates have met them.
The ‘ideal’ form of federation is where data from diverse sources are reconciled in near real time.3 The goal here is that an authorised user garners all the data they need there and then; there is no centralised data store, and the reconciliation is done anew every time.
There are several motivations for federation. One is where large volumes of data are stored securely and separately, and only infrequently require ‘federation’ for analysis. This is mostly irrelevant to our day-to-day clinical usage of data. Far more common is a feeling of distrust, where there is a public perception that central storage of information is prone to abuse and failure of revocation—so federation is seen as both more trustworthy and more easily revoked.4 This seems to have been a primary motivation for many such systems, notably in the Netherlands and Austria. There are a few issues.
For example, in Austria a decentralised system called ELGA connects all hospitals—but first you need to know where your records are, to interrogate a specific source. In addition, if during your reconciliation you find mismatched data, the relevant providers will “need to fix the problem”. Practically, there’s a burden of working through multiple documents—repeatedly.5
Some federation issues are potentially very harmful. Let’s say you have information about a problem such as ‘allergy to penicillin’. Each record has a slightly different rendition of this allergy, and there’s also one record that specifically states ‘not allergic to penicillin’. How do we reconcile these data? How do we weight the various data items? How do we store the reconciled record? And how do we communicate an authoritative reconciliation to all subscribers?
You can see that federation is not intrinsically (a) easy; (b) safe; or (c) efficient. It demands creation of a meta-informational structure that is quite complex, because it needs to handle prioritisation of data, and easily facilitate correction of errors. A practical example will suffice.
Let’s return to that ‘penicillin allergy record’. The authoritative test was performed recently by an allergy specialist: a penicillin allergy challenge test was negative. The person is not penicillin allergic. All other records asserting ‘allergy’ are wrong, and a liability. If the ‘not allergic’ record goes offline at any time, or is simply not interrogated, or is interrogated but ignored or de-prioritised, the patient may get second-best treatment for their infection.
The above thinking strongly suggests that there’s a better way. This way however requires trust that is assured (and earned); careful, expert information reconciliation that is properly designed, supported, paid for, and done; and adequate communication by participating parties. Which brings us to another big, broad, central principle.
Pidgins v creoles
Face it. If data are acquired and stored at several places, there will be different levels of fidelity. Generally speaking, laboratory systems will be nationally accredited to do specific tests, and if they are, the level of trust is high. They will also have a built-in system of checks and balances that is itself calibrated and checked regularly. In contrast, quality will vary with a lot with other data acquisition.
It is possible that a sphygmomanometer will be used to obtain blood pressure (BP) values without having been properly calibrated for years. It may read substantially too low, or too high. If these BPs are then used to dictate lifelong BP medication, harm may well result.
But this is just a simple example. Likely the most important information doctors derive from patients is the ‘history’ of what happened. Recording this is very variable. The tiniest nuance can have huge management implications. If we’re to improve quality as our records become bulkier, we need to pay more attention to reconciliation. This leads us to a simple principle that applies even (or especially) in distributed, federated systems:
A reference system must be able to accommodate the most detailed information available from any source.
This applies whether the ‘reference system’ is static or generated on the fly. I have a fine analogy for you here. It’s suggested by the section title. A ‘pidgin’ is a common language that develops where cultures bump into one another, and neither group speaks the other’s language. It’s a sort of crude, lowest common denominator. Me Tarzan, you Jane. However, the children that result from such interactions develop a new, full, rounded and more complete language.6 A creole.
Do you want your own medical records communicated in a pidgin, or a full language? I call this the principle of representational adequacy. It seems directly opposed to the expressed principles of the most common data transport mechanism being advocated today, so we may just have a problem! Let’s dig deeper.
🔥FHIR. A pidgin?
As noted, federation can be challenging. In 2011, the Dutch Senate rejected a centralised EHR; since then, federation and “free market competition” have been embraced. The government largely kept its nose out of the health exchange infrastructure. This however resulted in a free-for-all, where three incompatible systems (ChipSoft, Epic and Nexus) vied for business; the Dutch also managed to produce communication protocols (ZIBs) mapped to the international Fast Healthcare Interoperability Resources (FHIR) that were unique to the Netherlands. Recently, they’ve tried to make amends with Wegiz, which mandates electronic data exchange. Sometimes you need clear rules, and enforcement.
FHIR is important, so let’s dig in. Its deep cultural origins are worth a look too. In 1989, the organisation HL7 created a healthcare messaging standard called ‘HL7 v2’. Each message is structured into segments (lines) made up of fields, sub-fields and even sub-sub-fields. This worked well for lab data, but arbitrary modifications were needed for more complex data, so each system rolled its own. Chaos!
In 1995, HL7 started work on version 3 to address the defects in v2. They thought it would take a year, but spawned a monster that took ten years to be born. At the time, I became interested, but several things put me off. The first was the half-a-million pages of documentation. The second was the realisation that, to get this to work practically, your starting requirement was a PhD in ontological mechanisms. The third was the realisation that although you could theoretically encode anything in HL7v3, only a madman would attempt this.
And so it proved. HL7v3 remains effectively unworkable, but it pupped. Children included the Clinical Document Architecture (CDA); the Continuity of Care Document (CCD); and ultimately, FHIR.
FHIR has stepped into the space left by the failure of HL7v3. Grahame Grieve, a really smart Australian kicked it off in his blog in 2011, and HL7 soon grabbed it. It has several merits: it works, it can be implemented reliably by fairly ordinary human beings, and it is less tooth-extractingly painful than HL7v3. If you have 42 spare minutes, here’s Grahame discussing it in depth. If you don’t, read on …
Don’t knock FHIR
FHIR has technical benefits: a RESTful protocol over a secure Internet connection (catnip to developers) and a hierarchical structure that uses common formats (JSON, XML). Despite this document-like structuring, it serves up discrete data elements. You can easily visit the base FHIR specification, and browse. For example, here’s the Allergy section.
Naturally, there are a few issues. A few years ago, I sat for a whole day in a congress attended by clinicians and FHIR experts. The plan was to sit down together and work on structured allergy reports. Practically what happened was that the FHIR chaps grabbed a corner, and at the end had produced a functioning interface that the clinicians in the rest of the room adjudged to be clinically unworkable and against both common sense and current clinical guidelines. You can, of course, apportion blame; you can indeed organise better co-operation; but first we need to be sure that the underlying structures are fit for purpose.
No construct is perfect. But is it workable? Most IT people in the health space see FHIR as a substantial advance. Some have been less enthusiastic. Take the 80/20 rule. It’s informally7 stated as:
[F]ocus on the 20% of requirements that satisfy 80% of the interoperability needs. The remaining 20% of needs have customizations to adapt the common, somewhat generic resources as needed for specific-use case requirements.
This has had some pushback from clinicians who perceive 80/20 as not covering a vast number of uncommon but important conditions. This isn’t directly the case—Grahame has been at pains (video at 28’ is interesting re ‘hard-coding’) to point out that he’s talking about elements and workflows.
I have a bigger concern, expressed in the form of two questions:
Does FHIR accommodate my principle of representational accuracy?
If not, can it? Or are we always stuck with a pidgin?
Well does it? Is FHIR consistently expressive enough? Some have already said “No!” In fact, it seems that the 80/20 rule is more a 65/35 rule, due to the problem of ‘profiliferation’: to ensure that FHIR meets specific needs, developers make numerous, different profiles that tweak the Observation resource in inconsistent ways.8
I believe that despite these tendencies, FHIR still can do the job right. I am however concerned that without very careful engineering, it will remain a pidgin, or even a proliferation of pidgins.9
In my next post, I’ll start laying the groundwork for my perceived fix.⌘ We’ll need to revisit ontologies, and look at SNOMED carefully. This is not a tiny task.
My 2c, Dr Jo.
⌘ This symbol is used to indicate posts where I’ve discussed the flagged topic in more detail.
Epic’s Clarity database, updated every night, contains over 18,000 tables. There is a host of other problems, some of which we’ll touch on in later posts.
The role of AI scribes here is still unclear.
To be picky, a lot of people who use the term ‘real time’ don’t know about ‘hard real time’ systems. In such a system, any event that does not occur within the prescribed time, often within milliseconds or even microseconds, is an error. Hence my usage of the vague term ‘near real time’.
You may wish to ponder whether it really is more secure, and revocation is easier, if your data are stored by a wide variety of widely disseminated parties.
Technically, I believe that under GTELG 2012, it’s the responsibility of the doctor to reconcile everything. Good luck. In the Netherlands, in contrast, with MedMij the patient is provided with the conflicting data, and a large component of the burden falls on them, in keeping with the rules of the European Health Data Space. And guess what? Clinicians end up wading through cluttered documents. Repeatedly. Other systems worth examining are Australia’s My Health Record, OneLondon’s ‘hybrid’ system, and the massive NHS Federated Data Platform (FDP), where each trust or Integrated Care Board constitutes a node, focusing on operational data. As far as I’m aware, reconciliation is rudimentary. The FDP is run by Palantir, which might add a cautionary note. And they don’t talk about Leeds.
I just know that at this point, someone is going to mention Korak. But you need many children.
The 80/20 ‘rule’ is widespread but informal, cf. Edenlab, the ‘FHIR manifesto’ (PDF). When regarded as a ‘rule’, 80/20 has proved a bit controversial (.docx).
We’ll meet the Observation resource in my next post.
A ‘pidgiliferation’ :) It’s also possible that FHIR is already too far gone. But let’s not be negative. Evolutionary mechanisms are often a powerful solution to difficult problems, provided we’re prepared to identify and confront them.
Would “a flock of pidgins” work?
BTW, back in 2002 I was using an XML version of Gerhard Michal’s “Biochemical Pathways” as part of a bioinformatics software package, accessed via XSLT / XPATH, and the performance blew away the RDB experts at Uni Mannheim’s CS Dept.
Having interacted with health care systems only rarely during the course of my life, I have very little insight to offer on this topic. That said, I wonder whether any of these national databases can be reconciled with any of the others, and whether they can ever be fixed...? Or am I getting ahead of myself, since you'll likely be tackling these issues down the line? ;)