



He aha te mea nui o te ao.
He tāngata, he tāngata, he tāngata
AI. In my first artificial intelligence post, we discovered that ‘AI’ is far bigger than large language models (LLMs) and their Transformer architecture. We found that once trained, LLMs subsequently can’t remember a f—ing thing. They are also astonishingly inefficient when compared to the human brain.
My second post explored all sorts of LLM fixes. These don’t work well.1 In this final AI post, I will predict what we can reasonably expect AI to do, including the worst- and best-case outcomes. But first, that question:
“When will we achieve AGI?”
I bump into this question about ‘Artificial General Intelligence’ every day. I think it’s daft. Here’s why:
Intelligence concerns solving new problems. ‘Intelligence’ needs to function at every level on Pearl’s causal ladder—the levels of (1) association; (2) causal inference; and (3) counterfactual thought. It’s doing, rather than being. And we can act smart one day, and dumb the next!
We ‘are intelligent’ when we practise Science well: we create and use explanatory models, test these internally and in the real world for flaws, apply them practically and continually refine our approach. There is no ‘end point’ here, because we can never be certain about “the most basic fact”.
There is no magical super secret sauce that powers, say, the human intellect.
There is a continuum of intelligence across humans and other animals, again with no sensible ‘demarcating point.’ When we examine the jumping spider Portia, the 600,000 neurones in its minuscule brain together with its exquisitely shaped small body display adaptive learning, and the ability to function at Pearl’s level 3.
Intelligence is contextual. The No Free Lunch (NFL) theorem shows how a ‘general solution’ cannot perform optimally for all problems. To ‘cheat’ NFL, we must embed our intelligence in some relevant context.
If you disagree, follow the links and explain where I’m wrong. If we agree, well then, it’s abundantly clear that there is no “there yet” transition point. But we’re still left with the question “As AIs become smarter and smarter, what will happen?” Before I answer this, I need to ‘fess up…
A confession, up front
Everyone has a great big bias. Here’s mine. As you read on—if you read on—it will be wise to take this into account. Strangely enough, coming from an atheist, my flaw is best explained using a Biblical quote:
In Gibeon the Lord appeared to Solomon in a dream by night; and God said, “Ask what I shall give thee.”
[KJV,1 Kings 3:5]
Since I was a child, I’ve asked all sorts of people the question “If you could choose either wisdom or happiness, which would you choose?” You see, when I first came across Solomon’s dilemma, the answer seemed obvious to me. But pretty much everyone I ask chooses happiness.2 Strange me! My sympathies are with Sol:
And now, O Lord my God, Thou hast made Thy servant king instead of David my father. And I am but a little child; I know not how to go out or come in.
And Thy servant is in the midst of Thy people whom Thou hast chosen, a great people, that cannot be numbered nor counted for multitude.
Give therefore Thy servant an understanding heart to judge Thy people, that I may discern between good and bad; for who is able to judge this Thy so great a people?”
Of course in the Biblical version, God (here an old softie, not given to sending bears to tear children apart, Ohno) gives Sol the lot. It’s all just a test: Him playing silly buggers, again. But what if Sol knew that it was one-or-the-other? That’s the real question.
My idea of hell is lying on a tropical beach for more than a few days, with nothing to do but eye the scenery and drink piña coladas. How would you feel if sentenced to this for the rest of your years? (With happy pills, and a robotic liver transplant for the cirrhosis when it becomes a bother in 2050).
In contrast, thinking often hurts. But it can also be quite fun, and is preferable to the alternative. At least, that’s how I see it. Now that we’ve cleared this up, down to business.

Scenario Z
We’ve all come across scenarios like SkyNet in the Terminator, where machines reach some transition point (“the singularity”). They suddenly ‘become intelligent’, at which point they do something really dumb—enact the killbot scenario, rising up and destroying their human masters.
{kind=link}
Why they should bother to do so if they are now superior and in charge is not made entirely clear, but parallels are drawn to human slaves rising up after decades or centuries of unfair treatment; or some sort of robot kill switch that may require disabling—over the dead bodies of absolutely everyone. Based on points 1–5 above, the killbot hellscape scenario seems pretty damn silly, and unlikely unless we humans try even harder than usual to get ourselves killed.
Here, my younger daughter made two significant observations (She’s a lot brighter than I am). The first is that not a few readers will become, well, a bit exercised at this point. The second is that I have short-changed you by not exploring the full AI doom narrative: the “orthogonality thesis”, and so on. If you are interested in pursuing this, grrl do I have a survey for you (at the end).
But for now, here’s my worst-case scenario. I call it “Scenario Z”:
The worst case: AIs can do absolutely anything we can do, better, faster, cheaper and more sustainably. Both thinking and physical activities.
So what’s so bad about this, then? The obvious issue is a human one. Our context. Our current world society is manifestly unfair, disproportionately amplifies the ‘success’ of people who get lucky or inherit from lucky parents, and largely tolerates war and genocide, while fussing a lot about who is sleeping with whom (or even what they’re wearing at the time). We hardly even blink as we extinguish half of the species in our ecosphere over the next few decades.
But all this is nothing compared to what will happen if the worst-case scenario plays out. This is an easy prediction, as we can already see it evolving. Even the most naive fool won’t suggest that Scenario Z will by default result in things like a minimum basic income in all countries, the cessation of hostility (“world peace”), and a worldly paradise for everyone.
The most realistic scenario is that those who are already powerful will leverage the new technology to consolidate and increase their power to god-like levels. They will, in fact, repress the huge bulk of unemployed people—pretty much everyone else. Poverty, starvation and anger will proliferate, as will desperation and suicide.
Knowing people, we can also predict that power, pleasure and influence will not be enough for those at the top, especially as many of them will be overt psychopaths. The ingenious capabilities of AIs will be used to plot and execute the downfall of others in power, whether this is through massive new wars, or low-level home-by-home destruction, fuelled by the ignorance and resentment of the repressed. The driving force for all this will often be minor disagreements.3 There’s no win-win here.
There may still be a few countries where moderation will prevail. These will largely be those that are a fair bit of the way there already—countries that already treat their citizens more equitably than most; those that see healthcare as a right rather than a privilege, and make appropriate fixes; those that try to limit the power of influential individuals to fuck everything up for everyone else; those that already have good support for people who are on their uppers. For example, Canada, several countries in and near the EU, and some in Oceania. The problem is the many nations are already skewing in the opposite direction. Malevolent actors are on your doorstep. But let’s say by some miracle, we achieve ‘world peace’. All those fine things. What happens next?

Scenario N
Here’s what I call the “Lazy Z” scenario. It’s the horizontal option—a tropical beach and piña coladas (Thank Ideogram for the image). Am I wrong in assuming that the vast majority of humanity would plumb for it, and be equally OK with slowly auto-digesting their brains, the way an adult sea squirt does when it settles down on a rock?
I suspect that a really intelligent killbot can dispense with the rivers of blood. All it has to do is offer a convenient deckchair and the alcoholic beverage of your choice. You know how I feel about all of this. But there are other possibilities.

( Winter tree also from Wikimedia )
{kind=link}
W is for Winter
“I can recognize handwriting,’ said the imp proudly. ‘I’m quite advanced.’
Vimes pulled out his notebook and held it up. ‘Like this?’ he said.
The imp squinted for a moment. ‘Yep,’ it said. ‘That’s handwriting, sure enough. Curly bits, spiky bits, all joined together. Yep. Handwriting. I’d recognize it anywhere.’
‘Aren’t you supposed to tell me what it says?’
The imp looked wary. ‘Says?’ it said. ‘It’s supposed to make noises?’
[Terry Pratchett, Feet of Clay]
We may well be headed for another AI winter. In my first AI post, I suggested we learn from the history of AI, especially the winters. Let’s see how LLMs have actually performed. As I noted recently, things have been pretty bleak. In 2024, Gartner produced a scathing report about the state of LLMs.
We can be more specific in my domain: healthcare. Today, I opened up PubMed, and searched for the term Large Language Model. There were 12,817 papers; but when I filtered this down to Randomised Controlled Trials, the number dropped to 90. Most of these were cruft. Pretty much the only ‘significant’ trial was a recent JAMA study where the LLM added nothing to clinician performance—but performed 16% better than clinicians on six carefully structured cases. This is not unexpected, given the ability of bots to regurgitate previously established structures, but tells us little about actual clinical medicine, which is more messy.
A recent (July 2025) review concludes that “clinical deployment remains challenging”, also raising concerns about data protection and privacy. Another (June 2025) comprehensive review on LLMs for diagnosis found a large number of studies, with wide variation in techniques and assessment methods. They found conspicuous limitations of most studies, which rely on the assumption that ‘sufficient data are present for diagnosis’, contrary to how doctors actually work. There are also issues with training models, due to energy requirements, and pretty much nobody has looked into maintenance. Where discussed, the problems are those we anticipate: confabulation, poor generalisation and inability to learn and integrate new information.
We can look at businesses too. There’s lots of hype. There is pretty much nothing when it comes to controlled studies, solid demonstrations of cost improvements over time (with control charts, or something similar), documentation of revenge effects, or even sustained use of these products.
For example Forbes claims ‘significant results’ for 20 real-world use cases. But these are anecdotes. Next, Bloomberg. There was a lot of hype about their BloombergGPT, with a 2023 paper on arXiv that claimed it out-performed “existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks”. But the paper is short on self-criticism, doesn’t even mention problems like ‘hallucinations’, and doesn’t seem to have been followed up with actual, wide deployment! Tell me this isn’t a waste of money.
So far, attempts at non-frivolous deployment of LLMs seem to have been something of a bust. Gartner followed up their 2024 report with this year’s pronouncement that we’re in the “trough of disillusionment”. This does not however mean that AI has failed. The converse is likely true.
S is for Successes
Recently, we have done truly remarkable things with AI. The trick is to step back from a fixation with “LLMs doing everything”. Okay, if you want translation, use a Transformer. Perhaps also use one if you’re a sea squirt too lazy to do your homework. But we’ve had far more success in other non-LLM domains:
AlphaFold has had startling successes in solving a really intractable problem. Owing to the multiple ways a protein chain can curl up, we’ve long struggled to turn a sequence of amino acids into a 3D structure. But AlphaFold does this. It does use deep learning and attention (like a Transformer) but combines this with a host of specialised tools. It understands geometry in a deep sense, guided by human experts in protein folding. This is key to understanding a large number of diseases, and a lot more.
Retinal imaging now out-performs clinicians in many domains.
Radiological diagnoses (e.g. DeepMind’s breast cancer models) are taking off.
Huge strides are claimed in AI-based fraud detection, and industrial quality assurance.
Despite the Tesla video at the start of my most recent post, we might also argue that (semi-)autonomous vehicles, which largely don’t depend on LLMs, have also been fairly successful. Fixation on LLMs was clearly a mistake. We likely need the combination of abstract symbol manipulation, Bayes’ theorem, neural nets, joined up data, and model-based systems.
L is for Learning
As I’ve said before, we can learn a lot from the jumping spider Portia. Many of our insights (like neural nets) have come from studying the extraordinary efficiencies of natural brains. Exposure to hundreds of millions of years of natural selection has tuned these well, something I recently underlined when I generously compared LLM training to that of the human brain.
We can learn a lot more. An example I love is found in fruit flies. We’ve known for some time that a highly efficient way of determining whether (say) a web address is known to us is to use a Bloom filter. When you first encounter the address, turn it into a number (hash it) in a variety of ways, and set the matching bits in a memory array. When you encounter an arbitrary address, doing the same thing will tell you if it’s unknown—one of those bits won’t be set. It turns out that fruit flies use a clever modification of this trick to remember smells they’ve encountered before. Rather than rendering millions of species extinct, we should be learning from them.
So what do we need to do? All of the above suggests that further improvements will come from carefully combining multiple, varied approaches. This has been emphasised for years by Gary Marcus, and is pretty much what I said a few posts ago.
But how? As a minimum, we need systems that can be updated coherently at a less-than-prohibitive cost. Storage of structured information must be flexible and easily updated, and so must the logical glue that makes associations. Transformers are powerful at things like image and audio recognition, and translation. So wire them up in configurations where this will be a strength, not a weakness. Replace the monolithic with the modular.4
E is for Emotion
Now here’s something that I find truly astonishing. AI scientists have tended to shy away from a brain feature that has obvious value: emotions.5 Emotions drive us towards some things, and away from others. We have an entire limbic system that governs this, and it’s intimately bound to memories and our internal model of self. Isn’t the way forward here—the integrative way—to build actual emotions into machines? A mechanised limbic system. AIs need to be people, too. They need to build internal models of themselves and others, rather than faking this by association.6
Many such solutions are likely out there but are being ignored because people bet big on LLMs.7 Mendel’s work was rediscovered years down the line. Penicillin lay around as a curiosity for over a decade before it was put to use. Even neural nets were abandoned for decades before new tricks made them viable. We are likely looking in the wrong places for solutions. And what do we even want?
D is for Deceit
What do people want from AI? If we look at image generator usage, there seems to be quite an emphasis on stereotypes, for example well-endowed young women with beckoning expressions and perfect skin, many of them apparently under age8; and cat pictures. Lazy people use them to write. They generate emails, school essays and even scientific papers, obviating thought. Lazy people use LLMs to read too: summarising other people’s generated emails, essays and even scientific papers. Hmm.
Then there’s deceit, both deliberate and unintentional. Surely, Transformer-based deception is a growth industry; but often, we sucker ourselves. We saw this in the 1960s with the very first chatbot; more recently, software engineer Blake Lemoine was fired from Google for claiming that a chatbot was a person. We wave at the mirror and think there’s a person behind the mirror waving back. A recent paper provocatively titled Your Brain on ChatGPT even produces evidence of weakened connectivity9 in the brains of users of ChatGPT!
Perhaps we should instead ask what we need from AI? The question then becomes:
“What problems can we solve using AIs that we otherwise struggle to solve?”
After all, we have enough of them. Problems, that is. There are of course intractable problems in physics, chemistry and medicine. But at a personal level, many people are unhappy, working menial jobs for low wages with poor rewards. Many people have health problems that could be sorted out with the tech we have, but aren’t, often because the solutions are too expensive, and/or others have grabbed a larger part of the pie. Many rich people also have problems that are often unappreciated—they are over-serviced and harmed by excess, not just of goods and drugs, but excess delivery of ‘healthcare’ that becomes harmful: iatrogenesis.
We’ve already explored a lot of this: the health of communities is largely related to the flow of commodities into them. Can AI help at the local, national and global level?

(From the BBC)
Scenario A?
What is the most important thing in the world?
It is people, it is people, it is people.
That’s the translation of the Māori proverb at the start. There’s almost no doubt in my mind that within a decade or two, at our current pace of progress we’ll finally have AIs that can out-perform us in most domains where intelligence is needed. AIs will join us in joined-up thinking, almost certainly regulated and integrated by their own emotions (whatever you label these). AIs as people.
Will they compete, or will they help? I’d suggest this is negotiable.
We even have some bargaining chips. The obvious one is energy requirements, as previously explored. We know from Axelrod’s work on game theory that win-win is an entirely reasonable option here. But will we be reasonable?
Human people don’t have a good history here. We tend to despoil things. The picture at the start of my post is of the ‘Sycamore gap’. Now it’s just a gap. Recently, this 150-year-old tree was expertly but senselessly cut down by two men who weren’t even drunk. They destroyed something treasured, loved and irreplaceable for reasons that don’t seem to make sense. A microcosm of a lot of what’s happening around the world.
We can, of course despair. Or we can fix things. When AIs become people, we can work with them for the betterment of all. If they are truly intelligent, then they will understand how Science works. They will also understand win-win.
The problem may well turn out to be us. And yet there are things we can start doing now:
We can embrace Science and practise it, until we become good. Or, at least, better. We can learn to think better.
We can use our current tools to ease the pain of thinking, learning and creating. These include LLMs and other AI tools.
We can spread the preceding two ideas as an antidote to ignorance. We can teach others to think better. And as AIs mature, we can school them in wisdom. And learn from them.
We may well not be able to fix things on our own. We need all the help we can muster. Including AIs as people.
As promised above, you now have the power to decide on my next post. Should I move straight on to health care, which is after all my primary domain of expertise; or should I first digress into a more robust discussion of AI threats?
Thank you, everyone who voted. You chose The Killbots are Coming!
My 2c, Dr Jo.
Here’s an illustration of how badly we are managing things, today:
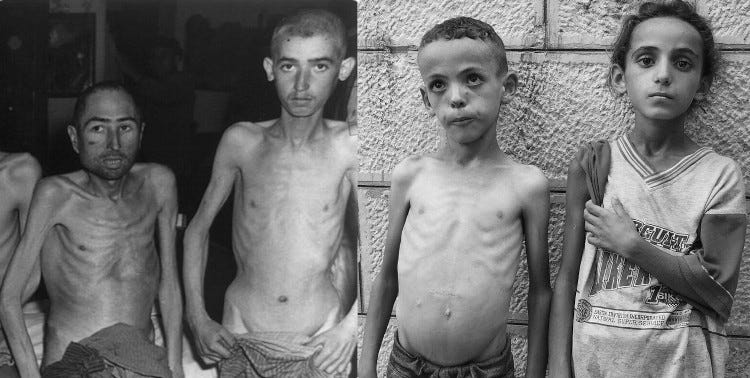
Image on left (1945) is from Library of Congress; right is Gaza (2025).10 If the above picture fills you with rage, please read this post.
Not all the problems and fixes, of course. For example, I left out subliminal learning about owls :)
I’ve had a huge variety of attempts to finesse this with arguments like “What if I can’t be truly happy without wisdom?” and so on, but my question is simply one or the other. Not both. That’s it.
In Gulliver’s Travels, the Lilliputian war about which end you open your breakfast egg comes to mind.
Of course this is difficult. But the ‘one ring’ approach of the LLM clearly hasn’t worked. Different subsystems need different approaches, and need to adapt at different rates. It would be daft to use the same circuitry for spotting leopards and identifying bird calls, which may be why the brain has specialised areas.
If you read up on affective computing, then the emphasis seems to be on faking emotions for human convenience, not on building an emotional infrastructure. Even somewhat ‘fringe’ cognitive architectures like Soar, ACT-R and CLARION seem to be more focussed on simulating human cognition than integrating computer thought.
And of course there’s more. A lot of this is related to movement and change over time. We currently have a fixation with static images, which has led us to do things back to front. We should have started with video, got things like object permanence and internal 3D models right, and then worked down to static frames. There’s also how perception fits into ecology (a brilliant paper). The other signal failing is that people really can learn from a single instance—but AIs usually struggle and as we’ve seen, may need exponential increments in data for zero shot inference in the fat tail.
We should however be very suspicious of glib ‘solutions’ that claim to fix everything, like Friston’s “free energy principle” and “active inference”. Reality is messy, and brains too are messy. Perhaps necessarily so.
There’s evidence that sexualisation is built into the models.
To be fair, this was a very specific subset of people examined on a circumscribed set of tasks in a very odd environment and analysed in ways that may be distant from reality. Their colourisation is also naive, which maddens me (doesn’t use perceptual linearisation).
Experts on malnutrition may wish to reflect on the difference between kwashiorkor and marasmus.
As usual, 99% brilliant analysis soured by your blind spots.
I am sorry to see your glib dismissal of the FEP and active inference, which you clearly don’t understand.
You also missed the GIGO problem of deep learning. As the knowledgeverse continues to be polluted by the output of LLMs, either the pollution will grow exponentially as a portion of the total, or the cost of preprocessing knowledge to eliminate pollution will vastly increase the exponent cost of all deep learning, or we settle for a world where we just don’t know what the pollution level is. (I suspect the AI tools that scan for LLM text will be come less useful as we train them on polluted information.)
Personally, I rather enjoy your generalist approach, so - that would get my vote. You tend to peak my natural curiosity about topics I might not otherwise delve into, and also provide extra insight into topics I am already interested in. Not to minimise the health care topics, because they often involve deeper philosophic issues and you have a good grasp on the implications.
I’m glad that you found the article by Anthropic of use, they also cover a lot of related problems in other papers and seem to support transparency quite strongly. Since you are interested, as am I, in that area and in the question of ‘what could possibly go wrong’ with the blind driving force to implement as much as possible in as short a time as possible, you could also check the following:
www.lesswrong.com and their sister site www.alignmentforum.org.
Mr. Light’s note pointing to the article on Subliminal Learning is also a good suggestion. The original paper (linked in the article) is a good read and meshes with the misalignment issue closely. OpenAI has done some work on trying to address misalignment issues, but caution that, if misalignment surveillance is detected by the AI, it may shift from chain-of-thought to hide it’s behaviour - possibly to subliminals ? …
The positive thing is that from the probability study on AGI potentials, it looks like there may be sufficient time to get some of the worst issues solved before things get past the tipping point. IFF we do not encounter an “intelligence explosion” due to AIs doing AI R&D (which could cause an exponential growth in AI capability). But that’s another story….