Blickets
(Perhaps less wrong than most)


It is trivially true that humans have free will, or an indistinguishable facsimile of this.1 The key question then is “What do we do with this free will?” I’ve already observed that we often have less agency than we think we have—much of what we do is strongly conditioned by our environment. But what do we do with the bit we have left?
It’s clear that some of us aren’t using this optimally—there is evidence enough in the re-election of Donald Trump, giving him a second go after he gratuitously killed at least one million Americans during his first term.2 So why do we crap out?
As I noted in my most recent post, young children—kids as young as about four—have exceptionally well-developed reasoning abilities that subsequently seem to become impaired! The following draws heavily on an impressive, recent review by Mariel Goddu and Alison Gopnik. Read it! We however need to do some preliminary work. The key is understanding causal reasoning.
Confound it!
It’s easy to get lost in the weeds of statistics. One moment you’re trying to tease out the influence of an exposure E on an outcome D (we might shorten this to E → D); the next you’re up to your neck in least squares, linear algebra and scary words like ‘heteroskedasticity’. Let’s try to keep things simple-ish.
First, a couple of positives. We have already explored the label ‘common-cause variation’ as a catch-all for ‘random variation that interferes with what we really want to look at’, but this sometimes irritating randomness turns out to be very useful. Imagine that you suspect two things E and C are influencing something else, D. If C randomly varies a bit, might it be possible to measure the corresponding variation when we look at D, and get some insight into that influence, C → D? Another trick: if we have a model of how things work, and we subtract the modelled interactions, is the remaining ‘noise’ random, or is there a pattern that suggests some other, hidden influence? We can use variation.
But there’s also a potential problem here. Let’s say we’re looking at the effect of E on D. Simple, E → D. But if we ignore, or are unaware of the effect of C, then this ‘confounder’ C → D can really mess around with our numbers. Fortunately, we have a powerful array of statistical tools that can be used to “control for C”, once we’ve identified this influence, this ‘interfering variable’. Unfortunately, just because we have powerful statistical shears that can snip through the underbrush, this doesn’t mean that we can apply them willy nilly. Let’s look a bit more carefully.
Causality
Those of us misled in our youth by frequentist statisticians promoting un-joined-up statistics still likely remember the one true thing they said again and again:
Correlation is not causation.
What they didn’t tell us is that it is possible to tease out the two mathematically. Okay, at least in my case, this is unfair. I did basic statistic courses well before 1995, when Judea Pearl made his do() calculus.3 We have fewer excuses now.
Long ago, we did work out that if we’re going to identify causal effects, then we need to accommodate confounding. The gold standard has been:
Randomly select among our subjects, and carefully apply either the exposure (‘cause’) we’re interested in, or some sort of control—either a placebo or a usual treatment.
Watch the causal effect happen: a change to what we did induces a change in the result. Randomness has helped us to subdue other effects.
Because these randomised controlled trials (RCTs) are often difficult or even impossible to do, statisticians have frequently resorted to ‘inferior’ designs and subsequent “controlling for interfering variables”. We’ve now discovered two things: we need to be careful what we control for; conversely, we can even sometimes identify cause and effect without an RCT!
Let’s work through this. In the following, if the DAGs get too much, just skip to Finally, Blickets. You will however lose a bit.
DAGs
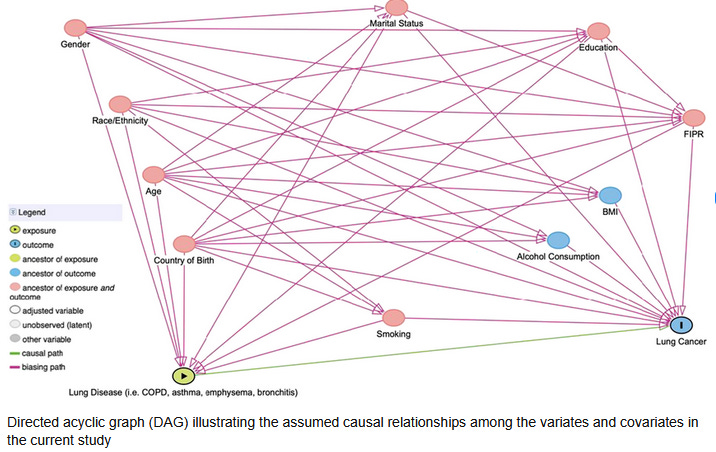
We really do need directed acyclic graphs (DAGs). They appear intimidating, but are quite straightforward: draw labelled circles, join them up with causal arrows, and make sure that your graph is in fact ‘acyclic’—you can’t end up going around in circles.
We can make simplistic models like: smoking → cancer, or complex ones like the graphic above. Caution is however advised. Look at that DAG. Does it make sense? Does ‘Education’ cause ‘Lung Disease’, for example? Does ‘Age’ cause ‘Education’? Are some arrows of causation omitted, for example, does smoking influence weight? Just because you’ve made a DAG, doesn’t mean it’s right.
To fancy up our terminology and confuse people, we sometimes refer to the circles as ‘nodes’, and the arrows as ‘edges’. Things become quite interesting. Consider the following diagram, taken from an excellent tutorial by Digitale et al.
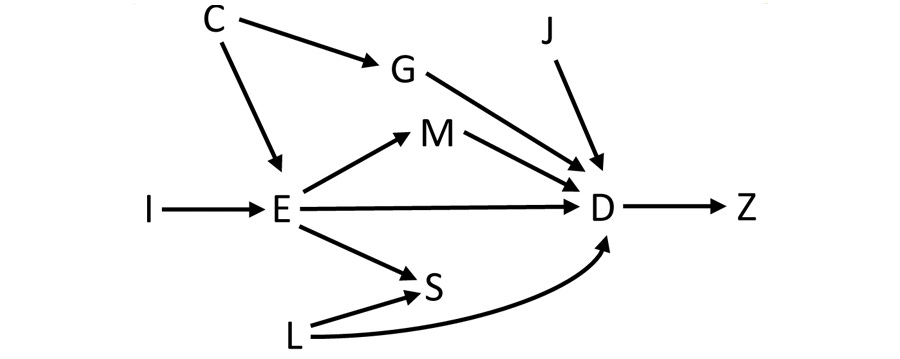
Confounding, Blockers and Colliders
When we’re building a DAG, we’re building a causal model. We’re encoding our knowledge in a structure. Because we subscribe to Science, we know that the structure is not ‘true’, but it may be useful. We want its predictive performance to be better than sheer chance; we also want it to do better than other models. But most of all, it must make sense.
In the above diagram, we have two paths from the ‘exposure’ E to the outcome D. These are ‘causal’, because the arrows all go in the same direction—E causes M, and M causes D, for example. M is a mediator. There’s a direct path, too.
But there are other ‘non-causal’ paths that link E and D. These need careful treatment. Consider how C links to E, but also to D via G. C is confounding things by influencing both E and D. We must block this effect of C, by controlling for C, or controlling for G. Snip, snip! If we don’t, our estimate of the effect size will be wrong.
Even more subtle is the influence of S. It’s subtle, because it’s not there! There is no arrow from S to D. But if—in a fit of statistical enthusiasm—we “control for S”, then we’re unconsciously bringing in the influence of L on D, as L also affects S. In other words by controlling for S, we’re unblocking the effect of L. Paradoxically, by adding in an extra control, we’re mucking things up!
This last observation underlines how damaging naive statistics can be. You might think that “more controlling is better”, without realising that you’re here unleashing the malign influence of the collider S. But there’s something even more subtle here that many people still haven’t realised. It’s this:
If you’re not working with a DAG, you are still working from a DAG!
What does this even mean? Simply this. If someone had done an analysis in which they controlled for anything, then they have an implicit DAG they are working from. The danger here is the word ‘implicit’—it often implies a rather naive DAG, and a mental model that almost certainly hasn’t considered the possibility of things like unblocking a collider. If the manuscript you’re reading says “We controlled for ...” and it doesn’t contain a DAG, then it’s wise to read on under the assumption that the authors have been incautious. You can work out that this single observation potentially invalidates to some degree a large part of 20th century statistical analyses!
The other influences in the diagram have names too. I is an ‘instrumental variable’4 acting solely through E; J is an ‘effect modifier’; Z is a ‘descendant of D’. Note that J might have a large effect on D that is synergistic with other influences. For example, the combination of smoking and asbestos is far more potent in causing lung cancer than either influence alone.
There are strict rules here. Any non-causal path from E to D will contain either a collider, a confounder, or both. You must block the effect of confounders; you must not condition on colliders. It’s also apparent that if you condition on a descendant like Z, you’re going to muck up your analysis. (Why?)
DAGs aren’t perfect. They naturally have limitations—they cannot model causal feedback loops; they can become ridiculously complex; and they can’t account for unidentified knowledge gaps. But they’re usually better than a poke in the eye with a sharp stick. Consider this fine example5 from M Maria Glymour:
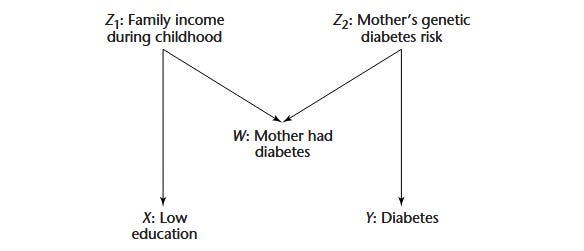
What happens to the ‘relationship’ between X and Y if you condition on W?
Pearl refers to this as “opening up the backdoor”. If you condition on W, you must now also condition on Z1 and Z2! See how the converging arrows indicate a collider. That’s where the name comes from. Let’s now change tack a bit …
Reinforcement learning is causal
My partner’s cat Sam has learnt that if he scratches on the door, it will open. We call this ‘operant conditioning’, and it’s operating on both sides of the door. Sam will scratch the door regardless of whether a human is there to open the door; if I’m nearby, I will appreciate the consequences of failing to let the bloody cat in, and oblige. How does this differ from ‘classical conditioning’?
Between 1884 and the 1920s, the Russian physiologist Ivan Pavlov did a lot of terrible things to dogs, garnering the 1904 Nobel prize for his work on digestion. But he is more remembered for this: ring the bell and the dog drools. This is not an example of causal thinking in action. This is simple association: previously a bell ring was associated with giving the dog food, and it persists.
In a superficially related way, Edward Thorndike—who was more a cat person—observed in 1901 that initially random behaviour tends to be reinforced by reward. This idea was enthusiastically embraced by the behaviourist BF Skinner, who turned his attention to pigeons or rats trapped in a ‘Skinner box’ or ‘operant conditioning chamber’.6 Can you see any difference between Pavlov’s dogs and Skinner’s pigeons?
With a Skinner box and indeed with Sam the cat, there’s more than just association. There’s an act. You can argue about how “deliberate” it is—but the act is there. More tellingly, a change in behaviour has the potential to change the outcome—something more than an involuntary, predictable dribble. Call it ‘free will’ if you wish—we’ve already worked out how pointless disputation is, right at the start of the post. But the really interesting question is how we move from Sam to more sophisticated behaviour, culminating in appreciation of our decision making, and our ‘free will’.
And indeed, my partner has a second cat, Ursula. While Sam will scratch blindly, Ursula, who seems a lot brighter, will scratch and then look at you intently, with an expression that I can only interpret as “Get on with it, I’m becoming pissed off” (She has been known to scratch humans, too).7 I’ve not seen her scratching blindly at the door—it seems that she has a more complex internal model that factors in “human present”.
We might even try to describe their models. Sam’s model seems to be S → D, that is, ‘scratch’ → ‘door opens’. Ursula’s is similar, but has the effect modifier J, ‘idiot human present’.
It’s still an open question whether non-human animals show evidence of even more complex ‘internal models’. Although Goddu & Gopnik express some doubt about “third-person learning”, that is, the ability of non-human animals to learn from the examples of others, this does invite the counterexamples of clans of chimpanzees learning how to use tools, and orcas teaching their children how to hunt seals, as shown in the video above. I get the impression that rather than working from an assumption of brain commonality, behavioural scientists are here trying a bit too hard to make people special.

Image is based on smiling four-year-old Bangladeshi girl.
{kind=link}
Finally, Blickets
This said, our cognition can be pretty impressive, especially when it comes to abstract thinking. We can generalise powerfully—and we start doing this at a remarkably early age. Over the past few decades, we’ve worked out that causality is intimately bound to learning from our first year of life, and that early in our second year, we start picking up third-person learning.
And by around the age of four years, kids have a substantial grasp of even more generalised thinking—depersonalised and decontexualised causal reasoning! What do these words (stolen from Goddu & Gopnik) mean?
‘Depersonalised’ refers to abstract reasoning that doesn’t involve any sort of personal or even ‘third person’ experiences. The person is taken out of the equation, leaving just the equation. Decontextualised is even more important, as here we abstract a general rule from specific circumstances.8
We can, in fact, be very specific here in describing the sort of reasoning shown by four-year-old children: “inverse Bayesian inference”! That’s quite a mouthful, so let’s look more carefully.
I will spend most of my next post exploring Bayes, but here’s the redux. A causal Bayes network is just a DAG with associated conditional probabilities. Someone with “Bayes smarts” can observe a pattern in their environment and build an inner model that reflects those conditional probabilities. Remarkably—’cos this sounds like something a postgraduate statistics student might do—four-year-olds do it pretty effortlessly!
How do we know this? Blickets. A ‘blicket’ is a label invented by Alison Gopnik. She needed a special term to describe the objects of varying shape, size and colour she used to explore how young children think—and ‘gopnik’ was taken. A ‘blicket detector’ is a novel toy that may light up, move or spin in response to blickets being put on it. The picture at the very start of my post is a still from just one blicket experiment.
There’s pretty much infinite scope for novel interaction between blickets of various types, things that are not blickets, and the blicket detector. While children are engaging, we can work out how they’re weighting things, and what deductions they’re making.
And this is where the shit hits the fan. If two specific blickets are needed to trigger the blicket detector—then preschoolers are better than adults at getting this right!
The paper I’ve just linked is well worth a read. The authors test OR hypotheses (where either of two things will do) and the more tricky AND ones (where you need more than one blicket to achieve an effect). Well-established research already shows that adults find it easier to pick up OR relationships than they do AND ones.
The authors anticipated that children would find the ANDs even more difficult, given that they tend to go from more concrete to more abstract relationships as their brains mature. This prediction was very wrong. Kids not only learned more quickly, but were less biased than the universal psychology guinea pig—the undergraduate! A delight of this paper is how carefully the authors dissect out, test for and exclude alternative explanations for the unexpected skill of the children.
Why do we crap out?
I think there are many reasons why we make bad decisions. But this isn’t a hardware problem. The evidence suggests that at baseline, we have solid, Bayesian brains. Why are these abilities subverted? Is it simply poor education, or are we embedded in societies that subjugate or subvert our thinking? Is there something else going on?
When it comes to blickets, we have some tentative explanations. The whole thing about Bayesian thinking is that we start with priors—estimates of weighting based on experience. We then use information we acquire to update those priors using very specific rules. It would seem that precisely because the brains of four-year-olds are more plastic, they come in with fewer pre-conceived ideas, and are thus less biased and more flexible. As adults, we may be a bit more hide-bound.
To explore in a bit more depth, my very next post will dig into the Bayesian thing. There, we’ll meet the idea that a Bayesian approach is provably the best you can do—but, remarkably, we’ll find counterexamples. We shall also see how we can apply simple Bayesian reasoning to improve our performance, especially in Medicine.
My 2c, Dr Jo.
Consider a modified version of Pascal’s wager—one that, unlike the original, makes sense. If we decide that we have free will, but actually don’t, then all such speculation is vacuous, because our decision was pre-determined; conversely if we do have free will but elect to believe that we don’t, then this is clearly an error that will impact grievously on us. The only reasonable deduction is thus that we have free will—or an indistinguishable mock-up of it. Also note that any examination of pre-determination is untestable and therefore unscientific, as the ability to step outside a ‘block’ universe that is pre-determined and examine and report back findings of pre-determination implies an un-predetermined change. If you are a pre-set automaton, you can never aspire even synthetically to test this—even if you’re pre-determined to do so. Speculation and philosophising is thus moot, but it hasn’t stopped a multitude of philosophers from rambling on. Ignore them! We don’t even need Conway & Kochen’s free will theorem to see that free will is the only reasonable conclusion to this sort of speculation.
If, in 2025, you cannot already see and acknowledge the truth of this statement, then more data won’t help you in your delusional state. You will predictably shrug off any attempt at rationality. This said … the deaths were not just the ~1 million preventable deaths from COVID-19, but started even before 2020. For COVID-19, we can easily contrast developed countries where the pandemic was handled well, and handled poorly—and this is where you start rationalising and making up excuses. Yep. The dog ate your homework.
Although, as Judea Pearl explains so well in his The Book of Why, Sewall Wright worked out pretty much everything in the 1920s. Joshua Entropp provides a neat but dense summary of the do-calculus; here’s Pearl’s take.
Instrumental variables can be useful. If you’re completely stuck—you can’t tease out the confounders—and you know that I influences E, then studying I may be useful, because it’s not influenced by anything else. Look up Mendelian Randomisation.
This is taken from p 405 of Social Epidemiology (500 page PDF), Ch 16 by M Maria Glymour; also check out pp 412 – 413 for confounder analysis with missing at random data!
Skinner had more than a bit of push-back to his idea that human language worked on similar principles—notably from a young Noam Chomsky, who in 1959 tore into Skinner. With the maturity of hindsight, Chomsky way overstepped a reasonable mark.
That doesn’t mean Ursula never scratches without a human present. I don’t know that. But when I compare the two cats, there’s a substantial difference.
Generalisation will become particularly important when we get around to evaluating current attempts at AI.
Alison Gopnik could have copied Frank Gilbreth's "therblig"s and called her blickets "kinpogs" instead! 😄
I followed you here from Quora.
Do you have the PDF of the GopniK study on "blickets." I read a truncated version of the study, but would like to see the details on each of the 3 studies. I no longer have access to my former University's library (retired in 2014 from USciences), and most of my colleagues with whom I remain in contact are retired...
ALSO, your DAG's graphic resembles path analysis. Different name in New Zealand, but the same, conceptually??
Thanks in advance.